I/O
Input과 Output의 약자로 데이터의 입출력을 의미한다.
문자 인코딩
데이터를 다른 형식으로 변환하는 과정이다.
문자 디코딩
인코딩 된 데이터를 원래 형식으로 복원하는 과정이다.
인코딩, 디코딩을 하는 이유
컴퓨터가 이해할 수 있도록 데이터를 Byte 형식으로 변경한다. 따라서 파일을 작성하려면 Byte 형식으로 변경해야 한다. 그리고 컴퓨터가 이해하는 언어는 사람이 보고 이해하기 어렵다. 따라서 디코딩을 하여 사람들이 보고 이해하는 언어로 변경한다.
InputStream

위 코드에 주석을 읽어 보면 "이 추상 클래스는 바이트 입력 스트림을 나타내는 모든 클래스의 슈퍼클래스 이다. InputStream의 하위 클래스를 정의해야 하는 애플리케이션은 항상 입력의 다음 바이트를 반환하는 메서드를 제공한다."이다. 위 주석에 설명처럼 InputStream은 추상 클래스이자 바이트 입력 스트림의 슈퍼클래스이다.
BUFFER에 대한 자세한 아래에서 설명을 하겠다. 일단 간단하게 설명하면 MAX_SKIP_BUFFER_SIZE는 SKIP_BUFFER의 최대 사이즈가 값이 2048Byte로 설정되어 되었다. 이는 2의 11승으로, 컴퓨터에서 바이트 코드로 처리할 때 최적화된 크기이다. 이런 2의 거듭제곱 값은 컴퓨터 연산에서 중요한 기준이 되므로 참고하면 유용하다. 이를 참고하고 DEFAULT_BUFFER_SIZE를 보면 DEFAULT_BUFFER의 크기는 16384Byte으로 2의 제곱승으로 설정되었다.

생성자 코드의 주석을 보면 "호출할 서브클래스의 생성자입니다."라고 되어 있다. 이는 InputStream이 추상 클래스이기 때문에 직접 객체를 생성할 수 없고, 이를 상속받는 서브클래스에서만 이 생성자를 호출할 수 있다는 뜻이다. 즉, InputStream은 추상 클래스이므로 객체를 생성하지 못하지만, 하위 클래스에서 super()를 통해 이 생성자를 호출하여 InputStream의 초기화 과정을 상속받을 수 있다.
InputStream를 보면 Closeable을 구현하고 있다.

위 코드를 보면 Closeable은 AutoCloseable을 상속하고 있는 인터페이스이다.
위 주석을 해석해보면 "Closeable은 닫을 수 있는 데이터의 소스 또는 대상이다. close 메서드는 객체가 보유하고 있는 리소스(예: 열린 파일)를 해제하기 위해 호출된다."이다.
close() 메서드의 주석을 해석하면 "이 스트림을 닫고 이와 관련된 모든 시스템 리소스를 해제한다. 스트림이 이미 닫혀 있는 경우 이 메서드를 호출해도 아무런 효과가 없다. AutoCloseable에 언급된 바와 같다. close(), 닫기가 실패할 수 있는 경우에는 세심한 주의가 필요한다. IOException을 발생시키기 전에 기본 리소스를 포기하고 내부적으로 Closeable을 닫힌 것으로 표시하는 것이 좋다."이다.
위 코드를 이해하기 위해서는 AutoCloseable의 코드도 필요하다.

위 코드를 해석해보면 "닫힐 때까지 리소스(예: 파일 또는 소켓 핸들)를 보유할 수 있는 개체이다. AutoCloseable 객체의 close() 메서드는 자원 사양 헤더에 객체가 선언된 try-with-resources 블록을 종료할 때 자동으로 호출된다. 이러한 구성은 신속한 해제를 보장하여 리소스 소진 예외 및 발생할 수 있는 오류를 방지한다."이다.
close메서드의 주석을 해석하면 "이 리소스를 닫고 기본 리소스를 모두 취소한다. 이 메서드는 try-with-resources 문으로 관리되는 개체에서 자동으로 호출된다."이다.
try-with-resources
Java7 이전에는 외부자원을 사용하고 나면 close 메서드를 호출해야 했다.
public static void main(String[] args) throws IOException {
FileInputStream fis = null;
try {
fis=new FileInputStream("temp/loop.dat");
long startTime = System.currentTimeMillis();
fis.readAllBytes();
long endTime = System.currentTimeMillis();
System.out.println("Full Time: "+(endTime - startTime));
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
} finally {
fis.close();
}
}위 코드에서 잘 보면 try블록을 통해서 FileInputStream에서 나오는 예외를 잡는다. 하지만 이 메서드를 보면 예외를 던지고 있다. 왜 그럴까? 잘 보면 아래에 close() 메서드가 있는데 이 메서드 때문에 IOException 예외를 던지고 있는 것이다. 실제로 위 코드에서는 close 로직은 그렇게 크게 중요한 로직이 아니다. 하지만 close 메서드 때문에 예외를 던지는 상황이다.
Java7부터는 이런 문제를 해결하기 위해서 try-with-resource를 사용했다. try-with-resource는 자원을 자동으로 반납해 준다. 아래 코드를 보면서 try-with-resource를 이해해 보자.
public static void main(String[] args) throws IOException {
try (FileInputStream fis = new FileInputStream("temp/loop.dat")) {
long startTime = System.currentTimeMillis();
fis.readAllBytes();
long endTime = System.currentTimeMillis();
System.out.println("Full Time: "+(endTime - startTime));
} catch (FileNotFoundException e) {
throw new RuntimeException(e);
}
}위 코드를 보면 아주 깔끔하다. close 메서드도 보이지 않는다. 또한 try-with-resource 코드를 보면 finally가 없어도 괜찮다. close 메서드를 사용해야 하는 외부 자원인 fis가 try 블록이 끝나자마자 자동으로 할당된 자원을 해제한다. try-with-resource 코드를 통해서 우리는 좀 더 직관적으로 이해할 수 있게 되었다.
OutputStream

위 코드에 주석을 읽어 보면 "이 추상 클래스는 바이트 출력 스트림을 나타내는 모든 클래스의 슈퍼클래스이다. 출력 스트림은 출력 Byte를 받아들이고 이를 일부 싱크로 보낸다. OutputStresam의 하위 클래스를 정의해야 하는 애플리케이션은 항상 최소한의 1Byte의 출력을 쓰는 메서드를 제공해야 한다."이다.

생성자 코드의 주석을 보면 InputStream과 같이 OutputStream도 추상 클래스이기에 같은 주석이 달렸다. 위에 쓴 글과 같이 하위 클래스에서 super()를 통해 이 생성자를 호출하여 OutputStream의 초기화 과정을 상속받을 수 있다.
위 코드를 보면 OutputStream이 구현을 하는데 Closeable, Flushable이 있는데 Closeable은 위 InputStream 코드와 같기에 남은 Flushable 코드만 보겠다.

위 코드에 주석을 해석하면 "Flushable은 플러시 할 수 있는 데이터의 대상이다. 플러시 메서드는 버퍼링 된 출력을 기본 스트림에 쓰기 위해 호출된다."이다.
flush() 메서드의 주석을 해석하면 "버퍼링 된 출력을 기본 스트림에 작성하여 이 스트림을 플러시 한다."이다. OutputStream을 기준으로 하면 flush() 메서드를 호출하면 OutputStream에 저장되어 있는 데이터를 기록할 파일에 write 한다.
FileInputStream
파일에서 데이터를 읽어오는 스트림이다.

위 코드에 주석을 해석하면 "FileInputStream은 파일 시스템의 파일에서 입력 바이트를 얻는다. 사용 가능한 파일은 호스트 환경에 따라 다르다. FileInputStream은 이미지 데이터와 같은 원시 바이트 스트림을 읽는 데 사용된다. 문자 스트림을 읽으려면 FileReader를 사용하는 것이 좋다."이다. FileReader는 나중에 설명하겠다.
read()
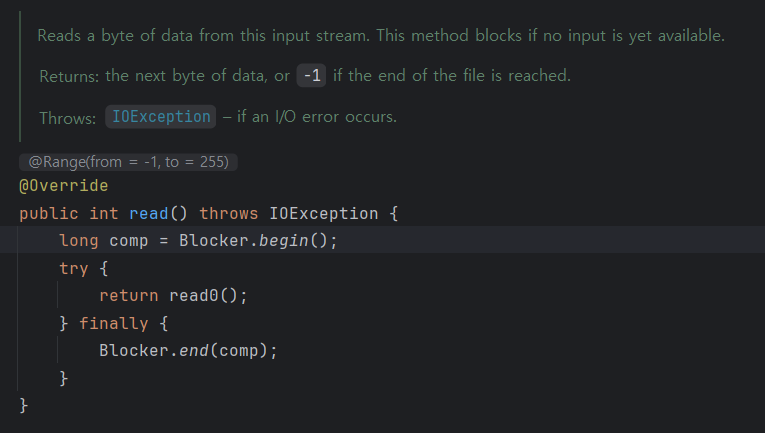
주석을 해석하면 "입력 스트림에서 데이터 바이트를 읽는다. 이 메서드는 아직 입력이 없으면 차단한다. 반환값: 다음 데이터 바이트를 반환, 파일 끝에 도달하면 -1을 반환한다."로 read 메서드는 파일에서 데이터를 byte 단위로 하나씩 읽어온다. 읽을 내용이 없으면 -1을 반환한다.
코드를 보면 Blocker 클래스에 대해서 사용하는데 위 코드의 형태는 Blocker 클래스의 사용 방식이다.
Blocker

위 코드에 주석을 해석하면 " 잠재적으로 블로킹 작업이 시작되고 끝나는 지점을 표시하기 위한 정적 메서드를 정의한다. 이 메서드는 다음과 같이 try-finally 블록에서 사용하도록 설계됐다. 가상 스레드에서 이 메서드를 호출하고, 해당 스레드가 CarrierThread(기저 스레드)에서 실행된다면, 이 블록의 코드는 ForkJoinPool.ManagedBlocker에서 실행되는 것처럼 동작한다. 이는 블로킹 작업 동안 추가 병렬 처리를 지원하기 위해 스레드 풀이 확장될 수 있음을 의미한다."이다.
long comp = Blocker.begin();
try {
// blocking operation
} finally {
Blocker.end(comp);
}위 코드 형식은 Blocker 클래스는 사용하면 사용해야 하는 코드 방식이다. 위 read() 메서드에서도 Blocker 클래스를 사용하기에 같은 패턴으로 사용하고 있다.
read 메서드를 보면 하나씩 읽어서 파일을 읽는다. 반대로 한 번에 읽어오거나 내가 원하는 만큼 크기를 정할 수는 없을까?
read(byte[] b, int off, int len)

위 코드에 주석을 해석하면 "입력 스트림에서 최대 len 바이트의 데이터를 바이트 배열로 읽는다. len이 0이 아니면 이 메서드는 입력이 가능할 때까지 블로킹(대기) 상태로 유지한다. 0이라면 데이터를 읽지 않고 0을 반환한다.
- b: 데이터를 읽어와 저장할 배열
- off: 배열 b에서 데이터를 쓰기 시작할 위치
- len: 읽어올 최대 바이트 수
읽은 총 바이트 수를 반환한다. -1이라면 스트림의 끝에 도달하여 더 이상 읽을 데이터가 없는 경우이다."이다.
read0(), readBytes(byte[] b, int off, int len)

위 메서드 코드에서 native는 다른 언어들(C, C++)로 작성된 라이브러리를 호출한다고 생각하면 된다. 그러므로 코드이름처럼 한 글자씩 read 하거나 byte크기를 정해서 파일을 읽는다고 파악하면 된다.
readAllBytes

위 메서드의 코드를 보면 너무 길기에 끊어서 보자 먼저 변수를 보면 length, position, size 순으로 읽을 데이터의 총길이, 파일에서 읽기를 시작할 위치, 남은 데이터의 크기이다. 다음으로 처음 if문을 보면 length나 size의 크기가 0 이하면 readAllBytes 메서드를 호출한다.

readNBytes 메서드는 파라미터의 크기만큼의 버퍼를 만들고 파일을 읽는다. 위 코드에서 Integer의 최댓값으로 버퍼를 만들고 파일을 읽는다.
그리고 다음 if문을 보면 size의 크기가 Integer.MAX_VALUE값을 넘는 경우 OOM(OutOfMemoryError)가 발생한다. OOM은 자료형의 범위를 넘는 숫자가 들어오면 원래 숫자가 아닌 다른 숫자가 출력되는 것을 의미한다. 즉 Integer.MAX_VALUE보다 큰 숫자가 들어오면 readAllBytes 메서드에서는 OOM 에러가 발생할 수 있다는 것을 인지해야 한다.
다음 for문을 보면 for(;;)으로 나와있는데 이는 무한 루프로 이해하면 된다. 다음 while문에서는 read(buf, nread, capacity - nread) 메서드는 buf 배열의 nread 위치부터 capacity - nread 만큼 데이터를 읽는다.
다음 if문에서 -1을 반환하면 파일의 마지막이라는 것을 의미한다. 또한 n이 0보다 작으면 이전 while문인 read 메서드 호출에서 EOF이 발생했거나, 추가적으로 1바이트를 읽는데 실패하면 무한 루프를 탈출한다. 즉 끝까지 파일을 읽거나 중간에 파일을 읽기에서 실패하면 무한루프에서 탈출한다.
만약 if문에서 탈출을 못했다면 이는 파일에서 원래 크기보다 더 큰 크기로 읽혔다는 말이다. 이 때문에 capacity와 buf의 크기도 재조정해야 한다.
마지막 return을 보면 만약에 추가적으로 읽힌 바이트 크기가 없으면 원래의 buf를 출력하고 파일이 처음에 알고 있던 크기보다 크다면 새롭게 배열을 copy 하여 출력한다.
FileOutputStream
파일에 데이터를 저장하는 스트림이다.
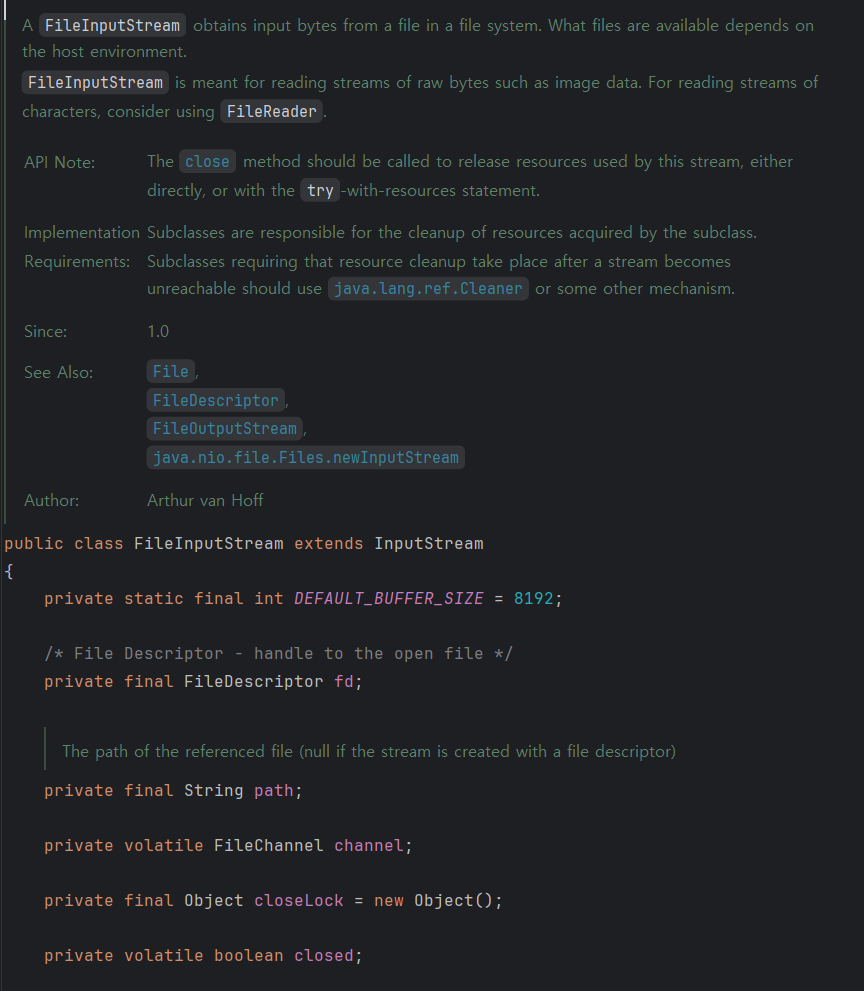
위 코드에 주석을 해석하면 "데이터를 파일(File) 또는 파일 디스크립터(FileDescriptor)에 쓰기 위한 출력 스트림이다. 이 클래스는 바이트 단위로 데이터를 출력하는 데 사용된다. 파일을 열거나 생성할 수 있는지는 운영체제 플랫폼에 따라 달라질 수 있다. 특정 플랫폼에서는 동시에 여러 쓰기 스트림을 열 수 없는 제약이 있다. 이미 열려 있는 파일에 대해 새 스트림을 생성하려고 하면, 생성자에서 오류가 발생한다. FileOutputStream은 이미지 데이터와 같이 원시 바이트 스트림을 파일에 기록하는 데 사용된다. 텍스트 데이터를 다룰 때는 FileWriter를 사용하는 것이 더 적합하다."이다.
write()

먼저 write(int b, boolean append) 메서드는 native 메서드이기에 자바가 아닌 네이티브 코드인 C, C++로 구현되어 있다. 메서드의 주석을 해석하면 "지정된 바이트를 이 파일 추력 스트림에 쓴다."이다. 즉 이 메서드는 바이트 값을 파일에 기록하는 동작을 수행한다는 의미이다.
write(int b) 메서드의 주석을 해석하면 "지정된 바이트를 이 파일 출력 스트림에 쓴다. 이는 OutputStream의 write 메서드를 구현한 것이다."이다. 즉 메서드가 전달받은 데이터를 파일에 기록한다는 의미이다. 나머지 코드는 위에 Blocker코드의 사용법과 동일하다.

write(byte[] b) 메서드를 보면 위 write(int b) 메서드와 매우 유사하다. 하지만 다른 점이 있는데 그것은 writeBytes()를 사용한다는 점이다. 이 메서드를 통해서 byte[] 크기를 한 번에 읽는 게 가능하다.
실제 코드를 사용해서 I/O에 대해서 공부해 보자.
파일 입출력 하는 법 - 하나씩 쓰고 읽기
private static final String FILE_NAME = "temp/loop";
private static final int FILE_SIZE = 5 * 1024 * 1024; // 5MB
public static void main(String[] args) throws IOException {
FileOutputStream fos = new FileOutputStream(FILE_NAME);
long startTime = System.currentTimeMillis();
for (int i = 0; i < FILE_SIZE; i++) {
fos.write(1);
}
fos.close();
long endTime = System.currentTimeMillis();
System.out.println("Full Time: "+(endTime - startTime));
}위 코드를 실행시키면 아래와 같이 23초의 결과가 나온다.

5MB 크기의 파일을 쓰는데 23초가 걸렸다. FileOutputStream을 사용하면 위 실제 코드에서 봤던 것처럼 하나씩 하나씩 문자를 쓴다. 즉 한 글자마다 write() 메서드를 사용한다. 그렇기에 5MB밖에 안 되는 크기에 파일이 23초의 시간이 걸렸다.
private static final String FILE_NAME = "temp/loop";
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream(FILE_NAME);
long startTime = System.currentTimeMillis();
int fileSize = 0;
int data;
while ((data = fis.read()) != -1) {
fileSize++;
}
fis.close();
long endTime = System.currentTimeMillis();
System.out.println("File size: " + (fileSize / 1024 / 1024) + "MB");
System.out.println("Full Time: "+(endTime - startTime));
}위 코드를 실행시키면 아래와 같이 14초의 결과가 나온다.

5MB 크기의 파일을 읽는데 14초가 걸렸다. FileInputStream을 사용하면 위 실제 코드에서 봤던 것처럼 하나씩 하나씩 문자를 읽는다. 즉 한 글자씩 read() 메서드를 사용한다. 그렇기에 5MB밖에 안 되는 크기에 파일이 14초의 시간이 걸렸다.
이제 성능을 높여보자.
Buffer를 사용하기
private static final String FILE_NAME = "temp/loop.dat";
private static final int FILE_SIZE = 5 * 1024 * 1024; // 5MB
private static final int BUFFER_SIZE = 8192; // 8KB
public static void main(String[] args) throws IOException {
FileOutputStream fos = new FileOutputStream(FILE_NAME);
long startTime = System.currentTimeMillis();
byte[] buffer = new byte[BUFFER_SIZE];
int bufferIndex = 0;
for (int i = 0; i < FILE_SIZE; i++) {
buffer[bufferIndex++]=1;
if (bufferIndex == BUFFER_SIZE) {
fos.write(buffer);
bufferIndex=0;
}
}
if(bufferIndex > 0){
fos.write(buffer);
}
fos.close();
long endTime = System.currentTimeMillis();
System.out.println("Full Time: "+(endTime - startTime));
}위 코드의 결과를 보면 아래와 같다.

와, 내가 원하던 속도가 드디어 나온다. 17ms 걸렸다. 위 코드는 Buffer를 사용하면 Buffer 크기가 차게 되면 Buffer 크기만큼 write를 해서 문자를 쓴다. 그렇기에 시간이 더 짧게 나오게 된다.
private static final String FILE_NAME = "temp/loop.dat";
private static final int BUFFER_SIZE = 8192; // 8KB
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream(FILE_NAME);
long startTime = System.currentTimeMillis();
byte[] buffer = new byte[BUFFER_SIZE];
int fileSize = 0;
int size;
while ((size = fis.read(buffer)) != -1) {
fileSize +=size;
}
fis.close();
long endTime = System.currentTimeMillis();
System.out.println("File size: " + (fileSize / 1024 / 1024) + "MB");
System.out.println("Full Time: "+(endTime - startTime));
}위 코드의 결과를 보면 아래와 같다.

하나씩 읽은 방법과 같은 5MB를 읽었지만 4ms의 시간밖에 걸리지 않았다.
이렇게 Buffer를 쓰면 더 빠르게 실행이 가능하다. 그러면 입출력을 사용하기 위해서는 직접 만들어야 하나? 자바 라이브러리에서는 이런 기능이 없을까? 자바에서는 BufferedStream 라이브러리를 제공한다.
BufferedStream
BufferedOuputStream은 위에 Buffer 기능을 내부에서 대신처리한다. 따라서 BufferedOuputStream를 작성하면 위 코드를 작성하지 않고 간단하게 작성이 가능하다.
private static final String FILE_NAME = "temp/loop.dat";
private static final int FILE_SIZE = 5 * 1024 * 1024; // 5MB
private static final int BUFFER_SIZE = 8192; // 8KB
public static void main(String[] args) throws IOException {
FileOutputStream fos = new FileOutputStream(FILE_NAME);
BufferedOutputStream bos = new BufferedOutputStream(fos, BUFFER_SIZE);
long startTime = System.currentTimeMillis();
for (int i = 0; i < FILE_SIZE; i++) {
bos.write(1);
}
bos.close();
long endTime = System.currentTimeMillis();
System.out.println("Full Time: "+(endTime - startTime));
}위 코드의 결과를 보면 아래와 같다.

BufferedInputStream도 위에 Buffer 기능을 내부에서 대신처리한다. 따라서 BufferedInputStream를 작성하면 위 코드를 작성하지 않고 간단하게 작성이 가능하다.
public static final String FILE_NAME = "temp/loop.dat";
public static final int BUFFER_SIZE = 8192; // 8KB
public static void main(String[] args) throws IOException {
FileInputStream fis = new FileInputStream(FILE_NAME);
BufferedInputStream bis = new BufferedInputStream(fis, BUFFER_SIZE);
long startTime = System.currentTimeMillis();
int fileSize = 0;
int data;
while ((data = bis.read()) != -1) {
fileSize++;
}
bis.close();
long endTime = System.currentTimeMillis();
System.out.println("File size: " + (fileSize / 1024 / 1024) + "MB");
System.out.println("Full Time: "+(endTime - startTime));
}위 코드의 결과를 보면 아래와 같다.
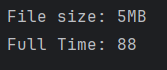
Buffer 기능을 내부에서 대신처리하기에 시간이 한 글자씩 처리할 때보다 118ms, 88ms로 줄었다. 하지만 이상하다. 왜 Buffer를 직접 사용했을 때보다 느린 걸까?
이는 동기화 때문이다. 실제로 라이브러리코드를 보면 멀티스레드 환경에서 사용이 가능하게 동기화과정이 포함되는데 이 때문에 직접 Buffer를 만들어서 사용하는 것보다 자바라이브러리의 write(), read() 메서드 실행 속도가 느리다.
BufferedOutputStream
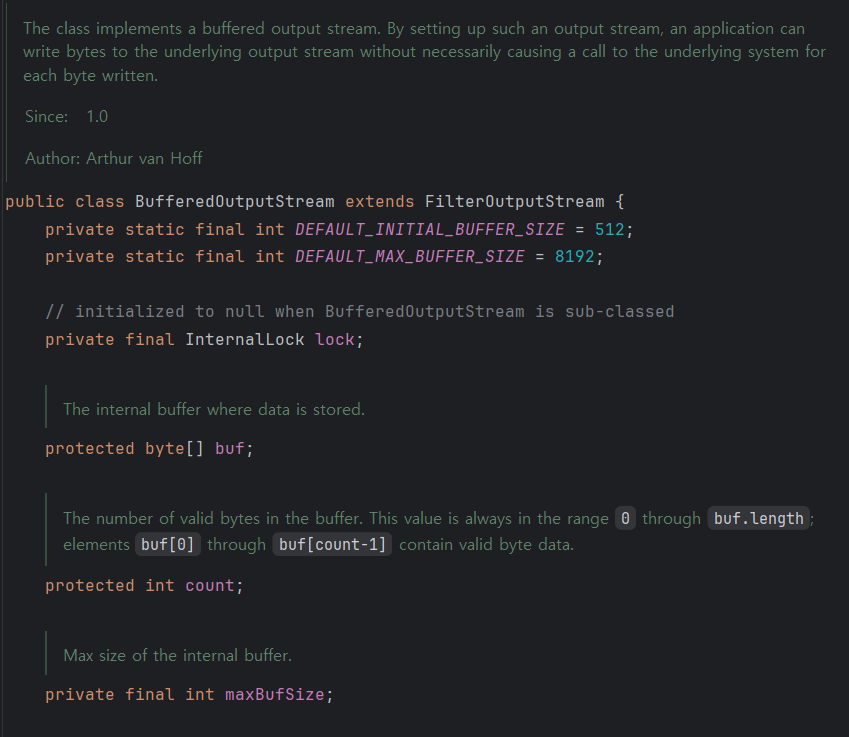
위 코드는 BufferedStream에서 봤던 것처럼 BufferedOutputStream은 buf 즉, Buffer로 코드를 처리한다. 또한 위 코드의 주석을 해석하면 "이 클래스는 버퍼링 된 출력 스트림을 구현한다. 이 클래스는 데이터를 한 바이트씩 출력하지 않고, 버퍼에 저장한 후 일정량을 모아서 한 번에 출력한다."이다. 다음 변수들인 buf 필드는 내부 Buffer이고 count의 주석을 해석하면 "이 변수는 Buffer 안에 현재 저장된 유효한 바이트의 개수를 나타낸다. count는 항상 0 ~ buf.length 사이의 값을 가진다. 버퍼 내에서 유효한 데이터는 buf [0]~buf [count-1]까지이다."이다.
위 코드에 필드를 보면 lock이 있다. 이는 동기화 객체로 이 라이브러리에서는 멀티스레드 환경을 생각하여 동시성 문제를 해결하기 위해서 동기화 객체인 lock을 지원한다.
BufferedOutputStream 생성자

위 코드는 BufferedOutputStream 클래스의 생성자 코드이다. 이 클래스의 파라미터를 보면 out, initialSize, maxSize 순으로 출력 스트림, 초기 버퍼 크기, 최대 버퍼 크기이다.
다음 super를 통해서 상속하고 있는 상위 코드를 통해서 생성자를 먼저 생성한다. if문을 보면 initialSize의 크기가 0이거나 그보다 작으면 예외를 던진다.
다음으로 if문을 보면 현재 클래스가 BufferedOutputStream 본래 클래스인지 아닌지 확인한다. 본래 클래스인 경우 내부 락을 사용하고 Buffer의 크기를 조절할 수 있다. 그래서 initialSize크기로 설정한다. 본래 클래스가 아닌 서브 클래스인 경우 lock이 아닌 모니터를 사용하고 Buffer의 크기를 조절할 수 없다. 그래서 maxSize를 사용한다. if문이 끝나면 maxBufSize를 설정한다.
그 아래 생성자를 보면 그냥 OutputStream만 있어도 되는 경우랑 크기를 설정해서 넣는 경우가 있다. 나머지는 this로 위 생성자를 호출한다.
write()

BufferedOutputStream의 write 메서드의 주석을 해석하면 "지정된 바이트를 버퍼에 기록한다."이다.
if문을 통해서 동시성 문제를 해결한다. 먼저 lock이 null이 아니면 lock을 걸고 implWrite 메서드를 호출한다. implWrite 메서드는 growIfNeeded(int len) 메서드를 호출한다. 만약 lock이 없으면 synchronized 블록을 사용해서 implWrite(int len) 메서드를 호출한다.
growIfNeeded를 호출하고 나서 if문에서 buf의 크기와 count값을 비교한다. 만약 count의 값이 큰 경우 flushBuffer 메서드를 호출한다. flushBuffer 메서드에서는 Buffer안에 값을 flush 한다.

그리고 배열 buf [count]에 (byte) b의 값을 넣고 count의 값에 +1을 한다.
growIfNeeded(int len)

먼저 필요한 사이즈인 neededSize 크기를 설정한다. 만약 크기가 0보다 작은 경우 Integer.MAX_VALUE 값을 준다. 그리고 Buffer의 크기를 설정한다. neededSize의 크기가 현재 Buffer의 크기보다 크고 현재 Buffer의 크기가 maxBufferSize보다 작으면 buf의 크기를 더 작은 수치로 설정하고 buf를 newSize로 copy 한다.
write(byte[] b, int off, int len)

위 write(byte[] b, int off, int len) 메서드 코드를 보면 write(int len) 메서드와 매우 유사한 코드를 가진다. 주석을 해석하면 "이 메서드는 주어진 바이트 배열 b의 데이터 중, off부터 시작하여 len 길이만큼 데이터를 버퍼에 저장하거나, 필요한 경우 즉시 하위 출력 스트림으로 데이터를 쓴다."이다.
코드는 위 write() 메서드와 유사하다. 호출하는 메서드인 implWrite(byte [] b, int off, int len)만 다르다.

위 코드를 보면 먼저 len의 크기가 maxBufSize보다 큰 경우 먼저 flushBuffer 메서드를 통해서 먼저 0부터 가능한 크기의 Buffer를 flush 한다. 그리고 off 값부터 나머지 값을 flush한다. 그리고 메서드를 끝낸다.
다음으로 len의 크기가 maxBufSize보다 작은 경우 growIfNeeded(int len) 메서드를 호출한다. growIfNeeded(int len) 메서드를 통해서 Buffer 크기를 설정한다.
다음 if문으로 통해서 len의 크기가 buf.length - count 값보다 큰 경우 flushBuffer를 통해서 buf의 값을 flush 한다. 그리고 System.arraycopy() 메서드를 통해서 요청된 데이터를 복사한다. 마지막으로 count의 값에 len을 더한다.
BufferedInputStream

위 코드는 성능 최적화 - Buffered 스트림에서 봤던 것처럼 BufferedInputStream은 buf 즉, Buffer로 코드를 처리한다.
위 코드의 주석을 해석하면 "BufferedInputStream은 입력 스트림에 버퍼링 기능을 추가한다. 버퍼링 기능이란 데이터를 한 번에 여러 바이트씩를 파일을 읽어 I/O 호출 횟수를 줄여 성능을 향상한다. mark와 reset 메서드가 있는데 mark는 스트림의 특정 지점을 기억한다. reset은 최근 mark 호출 이후 읽은 모든 바이트를 다시 읽을 수 있도록 한다."이다.
다음 변수로 DEFAULT_BUFFER_SIZE는 기본 퍼버의 크기로 8KB이다. EMPTY는 빈 바이트 배열을 의미한다.
다음으로 U가 있는데 U는 Unsafe 인스턴스이다. 이는 JVM 내부의 Unsafe 클래스를 사용하여 저수준 작업(메모리 접근, 오프셋 계산 등)을 수행한다. 여기서는 compareAndSetObject와 같은 비원자적 동작 대신 사용하여 종속성을 줄이고 애플리케이션의 부팅시간을 개선하려는 목적으로 사용된다.
BUF_OFFSET는 buf 필드의 메모리 오프셋이다. Unsafe를 사용하여 BufferedInputStream 객체의 buf 필드에 안전하게 접근하기 위해 계산된다. lock 내부 동기화를 위한 내부 lock이다. BufferedInputStream이 하위 클래스로 확장되면 null로 초기화된다. initialSize는 초기 버퍼 크기이다. buf는 내부 버퍼 배열로 데이터를 저장한다. buf가 null이면 스트림이 닫혔음을 나타낸다.
mark(int readlimit)
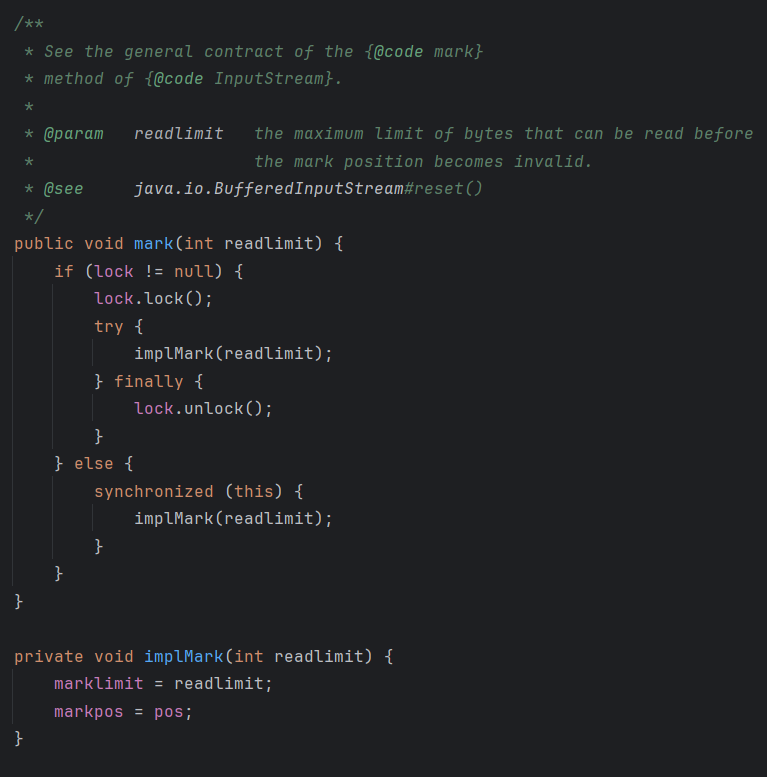
위 mark(int readlimit) 메서드 주석을 해석하면 "readlimit는 마크 위치가 무효화되지 전에 읽을 수 있는 최대 바이트 수를 설정한다."이다.
위 mark(int readlimit) 코드를 보면 다른 BufferedIuputStream의 write 메서드 코드와 유사하다. mark(int readlimit) 메서드도 유사하게 실행된다고 생각하면 될 것 같다.
reset()

위 reset() 메서드의 주석을 해석하면 "markpos가 -1인 경우 마크가 설정되지 않거나, 무효화되었음을 의미한다. 이경우 IOException 예외를 발생한다. markpos가 -1이 아닌 경우 pos를 markpos와 같은 값으로 변환합니다. 읽기 위치를 마지막으로 설정된 마크 위치로 변환한다."이다.
위 reset() 코드를 보면 다른 BufferedIuputStream의 write 메서드 코드와 유사하다. reset() 메서드도 유사하게 실행된다고 생각하면 될 것 같다. 다른 부분이 있는데 implReset() 메서드 부분으로 ensuerOpen() 메서드를 호출해서 스트림이 열여 있는지 확인한다. 그리고 markpos의 크기가 0이면 예외를 출력한다. 0이 아닌 경우 pos를 markpos와 같은 값으로 변환합니다. 읽기 위치를 마지막으로 설정된 마크 위치로 변환한다.
ensureOpen()

위 코드에서 ensureOpen() 메서드를 보면 스트림이 닫혀 있는지 확인한다. 만약 닫혀있다면 buf가 null로 예외가 발생한다.
read()

위 read 메서드를 보면 lock이 있다면 lock을 통해서 없다면 synchronized를 통해서 동시성 문제를 해결한다. 그리고 implRead 메서드를 호출한다. implRead메서드를 보면 현재 버퍼의 위치(pos)가 count보다 크면 fill 메서드를 호출한다. fill 메서드를 호출한 뒤 pos의 값이 아직도 count보다 크다면 스트림의 끝을 나타내는 -1을 출력한다. 아니라면 현재 위치(pos)의 바이트 데이터를 읽고 이를 unsigned 형식으로 변환하기 위해서 다음과 같이 &0 xff 연산을 수행한다. unsigned은 양수로 변환하는 것을 의미한다. 그런 다음 pos를 증가시켜 다음 위치를 가리킨다.
fill()

위 fill 메서드를 보면 fill 메서드는 내부 퍼버를 더 많은 데이터로 채우는 역할을 한다. 이 메서드는 mark와 관련된 상태를 관리하며, 버퍼가 부족하거나 더 커져야 할 때 이를 처리한다.
위 코드를 보면 getBufIfOpen메서드를 통해서 buffer을 출력한다. 이는 현재 스트림이 열려 있는지 확인하고, 내부 버퍼 배열을 가져온다. 스트림이 닫혀 있으면 예외를 던진다.
다음 if문을 보면 만약 markpos의 값이 -1이라면 pos의 값을 0으로 초기화한다. pos는 버퍼의 현재 위치를 의미한다. else if(pos >= buffer.length) 문을 보면 만약 pos의 값이 buffer의 크기보다 크다면 else if문을 실행한다. 다음 else if문안에 if(markpos >0)을 보면 markpos의 값이 0보다 크면 이전 데이터 중 mark 이후의 데이터만 유지하고 나머지는 버린다. 만약 else if(buffer.length >=marklimit) 문처럼버퍼가 marklimit보다 크거나 같으면 mark를 무효화하고 버퍼를 초기화한다. 그 외는 새 버퍼 크기(nsz)는 현재 크기(pos), 최소 성장값, 선호 성장값을 기반으로 계산한다. 새 배열(nbuf)로 데이터를 복사하고 Unsafe.compareAndSetReference로 기존 배열을 교체합니다. 실패 시 스트림이 닫혔음을 나타내는 예외를 던집니다.
다음 count=pos로 현재 읽은 위치를 업데이트한다. 다음줄을 통해서 내부 버퍼에 데이터를 읽고 버퍼 값을 추가한다. 읽은 데이터의 크기가 0보다 크면 count를 업데이트한다.
정리
FileOutputStream, FileInputStream 같이 단독으로 사용할 수 있는 스트림을 기본 스트림이라 한다.
BufferedOutputStream, BufferedInputStream의 생성자를 보면 OutputStream, InputStream과 같이 기본 스트림이 있어야 한다. 이처럼 단독으로 사용할 수 없고, 대상 스트림이 있어야 하는 스트림을 보조 스트림이라 한다.
글이 너무 길어져서 나머지 글은 다음글로 적겠다.
출처
https://mangkyu.tistory.com/217
'Java' 카테고리의 다른 글
| [Java] 스레드, 멀티스레드에 대한 공부 (0) | 2024.12.02 |
|---|---|
| [Java] 제네릭에 대한 공부 (0) | 2024.10.31 |
| [Java] 예외처리에 대한 공부 (1) | 2024.09.29 |
| [Java] 다형성에 대한 공부 (1) | 2024.05.01 |
| [Java] 상속과 구현에 대한 공부 (0) | 2024.04.12 |


