스레드
프로세스 내에서 실행되는 실행 단위이다. 이전 글을 보면 더 쉽게 알 수 있다.
멀티 스레드
한 프로세스 내에서 여러 스레드가 실행 단위를 나누어 실행되는 것을 의미한다. 자바 프로그램을 돌리면서 1개의 스레드만으로 여러 작업을 동시에 할 수 없다. 이에 자바에서는 여러 스레드를 만들어 실행시키는 방식으로 발전해 왔다. 이를 멀티 스레드라고 한다.
스레드의 상태
스레드는 여러 가지 상태를 가지고 있다.
- New : 스레드 객체가 생성되었지만, start() 메서드가 호출되지 않은 상태이다.
- Runnable : 스레드가 실행 중이거나 실행될 준비가 된 상태이다.
- Blocked : 스레드가 락을 기다리는 상태이다.
- Waiting : 스레드가 다른 스레드의 특정 작업이 완료되기를 기다리는 상태이다.
- Timed Waiting : 일정 시간 동안 기다리는 상태이다.
- Terminated : 스레드가 실행을 마친 종료한 상태이다.
Runnable, Thread
프로그램을 돌리면서 스레드를 사용하기 위해서는 Runnable 코드를 작성해야 한다.
스레드를 사용하는 코드는 Runnable, Thread가 있다.
Runnable (Java 21)

위 코드는 Runnable 코드이다. 위 코드를 보면 run() 메서드를 구현하는 인터페이스인걸 알 수 있다. @functionalinterface는 함수형 인터페이스인지 확인하기 위한 애노테이션이다. 함수형 인터페이스는 추상 메서드가 딱 하나만 존재하는 인터페이스이다. 함수형 인터페이스를 사용하는 이유는 람다식이 함수형 인터페이스로만 접근이 가능하기 때문이다.
Thread (Java 21)
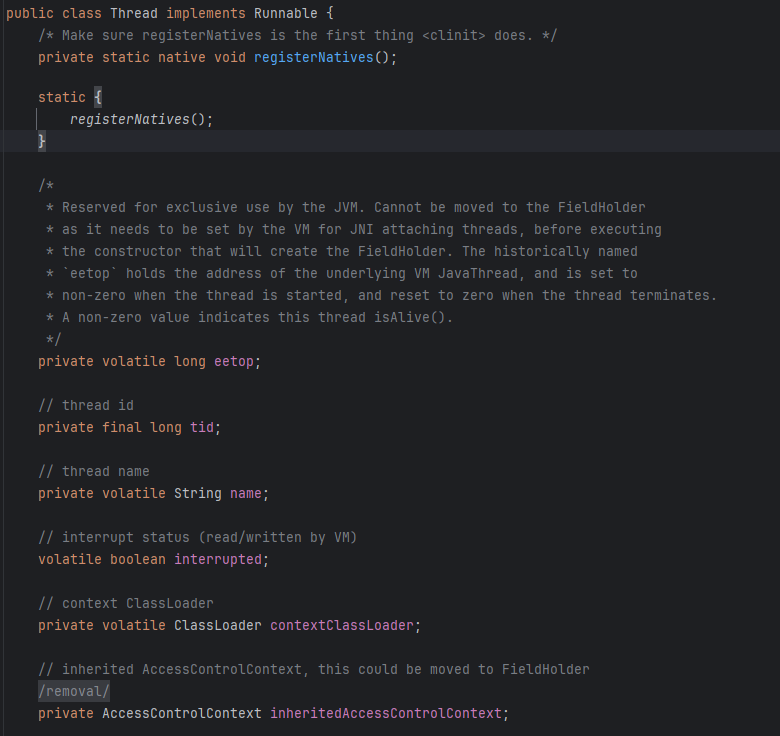
위 코드는 자바에서 있는 Thread파일이다. 맨 위 코드를 보면 Runnable을 구현한다. 즉 클래스인 Thread는 상속을 하게 되면 하나의 상속만 할 수밖에 없지만 인터페이스인 Runnable은 구현하면 다른 클래스를 상속하고 다른 인터페이스를 구현하는 게 가능하기에 Thread보다는 Runnable이 좀 더 유연한 사용이 가능하다.
JNI
Java 프로그램이 다른 언어로 작성된 프로그램과 상호 작용할 수 있게 해주는 인터페이스로 네이티브 코드를 호출하거나 C와 C++로 작성된 프로그램과의 상호작용을 위해서 사용된다. 위 필드에서 native void registerNatives가 있는데 native 메서드는 Java 외부에서 구현된 메서드(JNI)를 Java에서 호출하는 메서드이다.
volatile
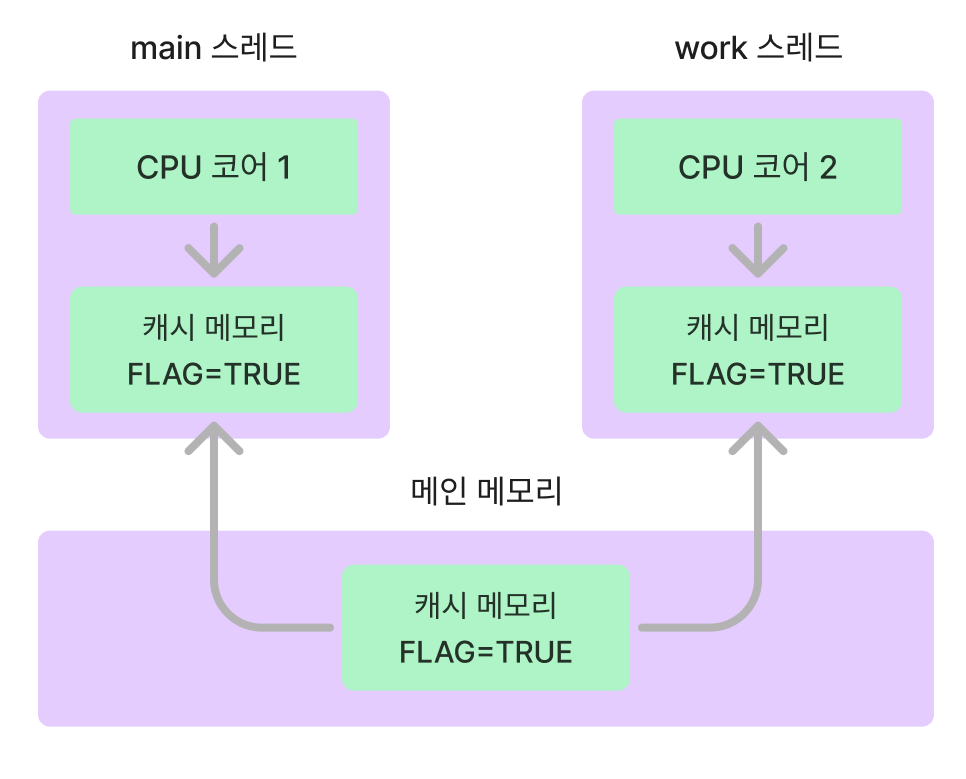
위 그림처럼 멀티스레드 환경에서 CPU 코어가 각각 할당되어 실행된다. 이는 각 스레드가 공유 자원인 FLAG를 효율적으로 처리하기 위해서 FLAG를 캐시메모리에 불러오고 캐시메모리에 값을 사용한다.

하지만 위 그림처럼 한 스레드에서 실제로 값을 변경했을 때 다른 스레드가 이를 알지 못하고 캐시메모리의 값으로 처리하면 공유자원인 FLAG를 FALSE값으로 인식하여 전혀 다른 값이 나올 수 있다.
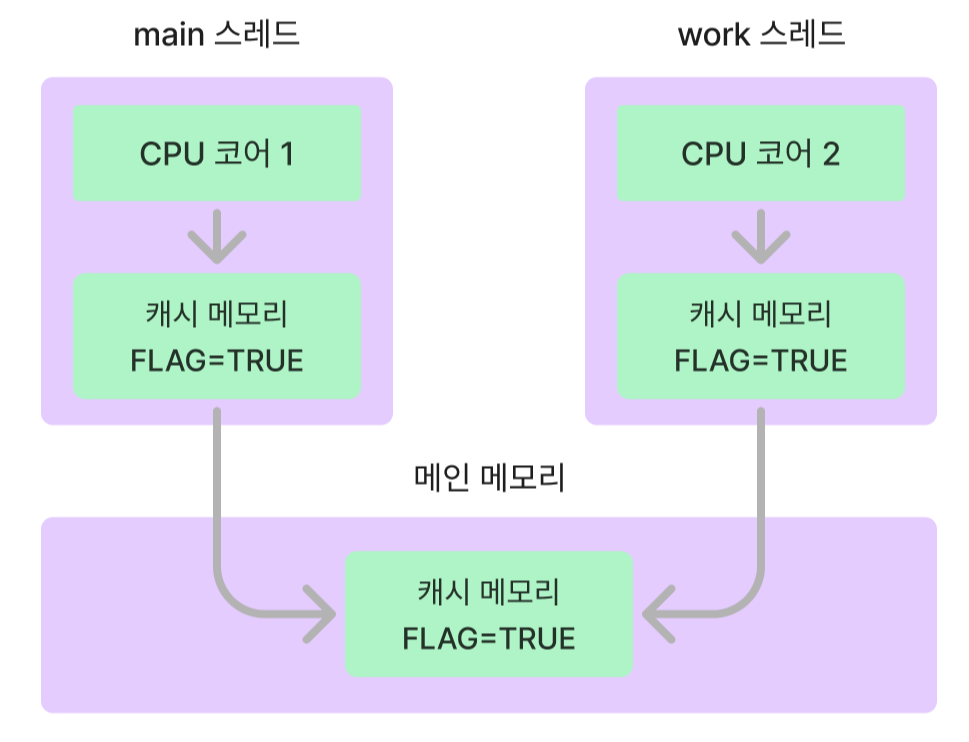
위 그림처럼 volatile을 사용하면 각 코어의 캐시 메모리가 아닌 메인 메모리의 값을 직접 접근하여 변경하기에 가시성을 보장한다. 실제로 캐시메모리가 아닌 메인메모리에 접근하기에 성능이 저하된다는 점을 유의해야 한다.
가시성
멀티스레드 환경에서 메모리에 변경한 값이 다른 스레드에서 보이는가, 보이지 않는가의 대한 문제이다.
private volatile long eetop
주석을 해석하면 JVM에서 독점적으로 사용하독록 예약되어 있다. FieldHolder를 생성할 생성자를 실행하기 전에 JNI 연결 스레드를 위해 VM에서 설정해야 하므로 FieldHolder로 이동할 수 없다. eetop은 기본 VM JavaThread의 주소를 보유하고 스레드가 시작할 때 0이 아닌 값으로 설정된다. 종료된 경우 0으로 재설정된다. 0이 아닌 값은 isAlive()를 나타낸다.
isAilve()

주석을 해석하면 isAlive() 메서드는 스레드가 살아있는지 테스트한다. 스레드가 시작되었지만 아직 종료하지 않은 경우 스레드는 활성 상태이다. 스레드가 살아있으면 true, 그렇지 않으면 false이다. alive() 메서드는 이 스레드가 살아있으면 true를 반환한다. 이 메서드는 final 메서드가 아니기에 재정의할 수 있다.
volatile interrupted
인터럽트가 발생했는지 안 했는지, 알 수 있는 값이다.
인터럽트
작업 중인 스레드를 중단시키는 기능이다. 강제로 종료하는 게 아니라 스레드가 스스로 인터럽트를 인식하고 종료하는 방식이다. 인터럽트는 Thread.sleep()처럼 블로킹 메서드에서 InterruptedException을 던진다. 즉 while문, 정상 로직에서는 InterruptedException가 발생하지 않는다. 예외가 발생할 때 예외를 잡아서 적절히 처리해야 한다.
public static void main(String[] args) throws InterruptedException {
Task task = new Task();
Thread thread = new Thread(task);
thread.start();
Thread.sleep(100);
System.out.println("main: thread 인터럽트 발생");
thread.interrupt();
System.out.println("main: 종료");
}
public class Task implements Runnable {
@Override
public void run() {
while (!Thread.currentThread().isInterrupted()) {
System.out.println("작업중");
}
try {
Thread.sleep(1000);
System.out.println("인터럽트 미발생");
} catch (InterruptedException e) {
System.out.println("인터럽트 발생");
}
}
}
위 코드는 while문을 탈출하기 위해서 인터럽트를 사용하는 코드이다. 그래서 인터럽트를 일부러 발생시키고 isInterrupted() 메서드를 통해 while문을 탈출한 후 인터럽트가 끝났기에 나머지 로직을 진행해 "인터럽트 미발생"이라는 출력이 나오는 게 예상 실행결과이다.

하지만 위 결과와 같이 실제로는, "인터럽트 발생"이 출력되었다. 왜 그럴까?
isInterrupted()

위 코드는 isInterrupted() 메서드 코드이다. 그저 interrupted를 출력한다. 이 점을 이해하고 과정을 다시 보면 스레드에 인터럽트가 발생되고 while문에서는 isInterrupted()가 true를 반환한다. 그래서 while문을 탈출한다. 하지만 여기서 그저 스레드의 interrupted의 값이 true, false 확인만 하고 넘어갔기에 다음 로직인 블로킹 메서드인 sleep()을 만나면 인터럽트 상태이기에 해당 스레드에 InterruptedException이 발생한다. 그래서 "인터럽트 미발생"이 아닌 "인터럽트 발생"이 출력된다.
interrupted()
while (!Thread.interrupted()) {
System.out.println("작업중");
}이를 해결하기 위해서는 위 코드처럼 isInterrupted() 메서드 대신에 interrupted() 메서드를 사용하면 된다.

위 코드는 interrupted() 메서드의 코드이다. 위 코드를 보면 현재 메서드의 getAndClearInterrupt() 메서드를 호출한다.

getAndClearInterrupt() 메서드는 위 코드와 같다. 위 코드에서 보면 만약에 인터럽트가 발생한 경우 true인 interrupted값을 false로 변경하고 clearInterruptEvent() 메서드를 호출하고 원래의 값을 반환한다.

clearInterruptEvent() 메서드는 위 코드와 같다. 외부메서드를 호출하는데 인터럽트를 clear 하는 메서드라고 생각하면 될 것 같다.

본문으로 돌아와서 interrupted() 메서드로 코드를 실행하면 결과는 예상 결과와 같은 "인터럽트 미발생"을 출력한다.
private volatile ClassLoader contextClassLoader
classLoader(클래스로더)는 자바는 동적 로드, 즉 컴파일 타임이 아니라 런타임에 클래스 로드하고 링크하는 특징이 있다. 이 동적 로드를 담당하는 부분이 JVM의 클래스 로더이다. 정리하자면, 런타임에 동적으로 JVM에 로드하는 역할을 수행하는 모듈이다. 간단하게 설명하면 자바에서는 바이트 코드인 '.class'를 JVM에 의해 메서드 영역에 저장하는데 이때 저장하는 역할을 하는 게 클래스로더이다. 좀 더 많은 역할을 하지만 classLoader는 다음 글에서 다루어 보자
java.security.AccseeControlContext
자바 언어에서 보안 관련 기능을 제공하는 클래스중 하나이다. 자바 보안 모델에서 권한 검사를 수행하기 위해서 사용된다.
start()

위 코드처럼 start() 메서드를 주석을 해석하면 이 스레드가 실행을 시작하도록 예약합니다. 스레드는 현제 스레드와 독립적으로 실행됩니다. 스레드는 최대 한 번만 시작할 수 있습니다. 특히 스레드가 종료된 후에는 다시 시작할 수 없습니다. IllegalThreadStateException은 스레드가 이미 시작한 경우 예외이다.
위 코드에서 synchronized는 멀티 스레드 환경에서 스레드가 한 번에 하나만 실행하도록 하는 도구이다. 로직을 보면 synchronized 블록을 시작한다. 주석을 해석하면 threadStatus에서 0은 NEW를 의미한다. 그리고 if문을 로직을 실행하는데 스레드 상태가 NEW가 아니면 start0() 메서드를 호출한다. 만약 NEW라면 IllegalThreadStateException이 발생한다. 이 예외는 스레드가 요청된 작업에 적합한 상태에 있지 않음을 나타내기 위해 발생한다.

위 코드처럼 start0는 외부 메서드를 호출한다.
run()
스레드 내에서 run() 메서드는 아래와 같이 보인다.

위 그림을 간단하게 설명하면 task의 값이 있으면 if문 로직을 실행한다. scopedValueBindings() 메서드를 통해서 이 스레드의 scope를 가져온다. runWith() 메서드를 호출한다.

위 코드의 주석을 해석하면 "범위가 지정된 값 바인딩은 ScopedValue 클래스에 의해 유지된다."이다. 현재 스레드의 scope를 가져오는 메서드이다.
ScopedValue
자바 21 기능에 추가된 기능이다. 이는 메서드 매개변수를 사용하지 않고 메서드를 안전하고 효율적으로 데이터를 공유할 수 있도록 한다. 기존의 ThreadLocal이 갖는 문제점을 해결하기 위해 등장했으며, 값이 특정 scope 내에서만 유효하도록 제한한다. scopedValue의 더 자세한 내용은 다음에 글로 다루어 보자
runWith()

위 코드의 주석을 해석하면 "VM은 이 메서드를 특별하게 인식하므로 이름이나 서명을 변경하려면 JVM_FindScopedValueBindings()에서 해당 변경이 필요합니다."이다. 로직을 실행하면 ensureMaterializedForStackWalk() 메서드를 실행한다. 후에 스레드의 run() 메서드를 호출한다. 마지막으로 reachabilityFence() 메서드를 호출하여 현재 객체가 GC가 대상이 되지 않게 한다.

위 코드에서 @IntrinsicCandidate은 메서드가 JVM 내부적으로 최적화될 수 있는 메서드임을 나타내는 애노테이션이다.

위 코드에서 reachabilityFence 메서드는 JVM에서 가비지 컬렉터(GC)가 특정 객체를 너무 빨리 대상이 되지 않도록 ref 객체를 참조한다.
@ForceInline
은 HotSpot VM이 메서드 또는 생성자를 인라인 할 때 표준 인라인 메트릭을 무시할 경우 메서드 또는 생성자에 "인라인화 강제(ForceInline)"라는 주석을 달 수 있다. 이 애노테이션은 최대한 사용을 자제해야 한다.
Inline
자바 컴파일러나 JVM이 메서드 호출을 제거하고, 메서드의 내용을 호출한 자리로 직접 삽입하는 최적화 기법이다. 글만 보면 무슨 뜻인지 이해하기 어렵다.
public int add(int a, int b) {
return a + b;
}
public void calculate() {
int result = add(5, 10); // 일반적인 메서드 호출
}public void calculate() {
int result = 5 + 10; // 메서드 호출이 제거됨
}위 코드처럼 1번째에서 2번째 코드로 변경하는 것을 의미한다. 이를 Inline이라 한다.
start() vs run()
위 Runnable코드를 보면 start()는 없고 run()만 구현하도록 되어 있다. 우리는 run() 메서드를 호출하면 되지 않을까? start()가 아닌 run() 메서드를 호출해도 되는 거 아닐까?라는 생각을 할 수 있다.
public class ThreadMain {
public static void main(String[] args) {
System.out.println("Main 실행");
Thread runnable = new Thread(new RunnableTest(), "runnable");
Thread thread = new ThreadTest();
runnable.run(); // 이렇게 실행 가능한가?
thread.run();
System.out.println("Main 종료");
}
}
public class ThreadTest extends Thread{
@Override
public void run() {
System.out.println("Thread 실행");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("Thread 종료");
}
}
public class RunnableTest implements Runnable{
@Override
public void run() {
System.out.println("Runnable 실행");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
System.out.println("Runnable 종료");
}
}위 코드에서 보면 start()가 아닌 run()을 사용하는 데 사용하는 데는 문제가 없다. 위 코드를 보면 main을 실행하고 runnabletest, threadtest순으로 실행되지만 sleep(1000)으로 인하여 main이 가장 먼저 끝나고 runnabletest, threadtest 순이라고 결과를 예상할 수 있다.

위 코드의 실행 결과이다. 뭔가 이상하다. 나는 Thread를 실행시켰고 일부러 1000ms의 시간을 두어 main이 가장 먼저 종료가 될 거라 예상했다. 하지만 runnable > thread > main순으로 종료가 되었다. 왜 이런 결과가 나올까?

위 그림은 내가 run을 호출할 때 내가 생각하는 멀티스레드 코드 실행 그림이다.

하지만 실제 코드는 위 그림과 같다. run() 메서드는 그냥 메서드를 호출해서 Main Thread에서 처리하는 싱글 스레드 방식으로 처리하는 것과 같다.
본론부터 말하면 run() 을사용해도된다. 하지만 run()을 사용하면 멀티스레드가 아니 싱글 스레드의 형식을 가진 코드가 된다. 그래서 run()이 아닌 start()를 하면 멀티스레드의 형식을 사용이 가능하다. 따라서 start() 사용해야 한다.

위 결과는 start()로 변경했을 때의 결과이다. 내가 생각하는 코드 값을 도출하기 위해서는 start() 메서드를 사용해야 한다.
스레드 동기화
여러 스레드가 동시에 공유 자원에 접근할 때 발생할 수 있는 데이터 불일치 문제를 방지하기 위해 간섭하지 못하도록 막는 것을 스레드 동기화라고 한다.
공유자원
여러 스레드가 함께 사용하는 자원이다.
임계영역
여러 스레드가 동시에 접근하면 데이터 불일치나 예상치 못한 동작이 발생할 수 있는 위험한 영역을 말한다.
동시성 문제
멀티스레드를 사용하면 임계 영역에 여러 스레드가 동시에 접근하여 동시성 문제가 발생할 수 있다.
public class Counter {
private int count = 0;
public void increment() {
count++;
}
public int getCount() {
return count;
}
}
public class Main{
public static void main(String[] args) throws InterruptedException {
Counter counter = new Counter();
Runnable task = () -> {
for (int i = 0; i < 1000; i++) {
counter.increment();
}
};
Thread thread1 = new Thread(task);
Thread thread2 = new Thread(task);
thread1.start();
thread2.start();
thread1.join();
thread2.join();
System.out.println("Final count: " + counter.getCount());
}
}위 코드에 대해서 설명하면 count를 멀티스레드 환경에서 2개의 스레드가 1000번씩 count++를 하는 간단한 코드이다. 이 코드의 예상출력은 "count: 2000"이다.

하지만 실제로 출력은 위 코드와 같이 값이 다르다. 이 값은 고정되어 있지 않고 실행마다 다르게 나온다. 실제로 2000이 나올 때도 있다. 왜 그럴까?

위 그림처럼 Thread 1과 2는 다른 스레드에서 접근하기에 동시에 실행되는 경우가 있다. 이런 경우 공유 자원인 count는 increment() 메서드를 따로 계산하여 2번이 아닌 1번만 호출하게 된다. 그래서 원하는 값인 2000이 아니라 1964라는 값이 나온다.
이를 해결하기 위해서는 어떻게 해야 할까?
synchronized
자바에서 synchronized를 사용하면 한 번에 하나의 스레드만 실행할 수 있는 코드 구간이다. 이를 통해서 임계 영역과 공유자원에서 원하는 값을 도출이 가능하다.
public class Counter {
private int count = 0;
public synchronized void increment() {
count++;
}
public synchronized int getCount() {
return count;
}
}
위 코드처럼 변경하고 코드를 실행하면 몇 번을 해도 위 결과처럼 2000이 나오게 된다. 하지만 synchronized는 한 번에 하나의 스레드만 실행하기에 성능의 저하를 일으킨다. 따라서 사용할 때는 필요한 부분에만 사용을 해야 한다.
synchronized를 사용하면 어떻게 하나의 스레드만 실행하게 할 수 있을까?
monitor lock
모든 객체는 내부에 자신만의 lock을 가지는데 이를 모니터 락(monitor lock), 고유 락(intrinsic lock)이라고 부른다. synchronized를 사용하면 지정한 객체의 monitor lock이 접근한다. monitor lock은 한 번에 하나의 스레드만 접근할 수 있도록 JVM이 지원하며 나머지 스레드는 대기를 한다. 블록이 끝나면 JVM은 대기하던 다른 스레드를 한 번에 깨우게 되고 그중 하나의 스레드만 접근하게 한다. 그렇기 때문에 위 코드에서 동시에 실행되지 않고 monitor lock을 얻은 스레드만 실행을 할 수 있다. 이때 대기 중인 스레드는 BLOCKED상태를 가진다. monitor lock과 BLOCKED 상태는 synchronized에서만 사용된다.
synchronized 코드 블록
public void increment() {
System.out.println("increment 실행 전: "+count);
synchronized(this){
count++;
}
System.out.println("increment 실행 후: "+count);
}위 코드처럼 synchronized는 메서드뿐 아니라 위 형태처럼 코드 블록 형식으로도 사용이 가능하다. 실제로 메서드에서 같이 사용해도 문제가 없는 부분에서는 그냥 사용하다가 동기화가 필요한 부분만 코드 블록으로 사용이 가능하다. 그렇기에 필요한 부분에만 synchronized을 사용해야 한다.
lock에 대한 설명을 보면 대기가 끝나고 접근할 때 여러 스레드 중에 어떤 스레드가 lock을 얻는지에 대해서 알 수가 없다. 이 문제 때문에 스레드가 무한으로 대기하는 문제가 발생한다.
이 문제를 해결해기 위해서는 어떻게 해야 할까?
lockSupport
LockSupport는 synchronized에서 발생하는 무한대기 문제를 해결할 수 있다. LockSupport는 스레드를 WAITING 상태로 변경한다. 이걸 어떻게 해결이 가능할까? 먼저 WAITING 상태는 누가 깨워주기 전까지는 계속 대기하고 CPU 실행 스케줄링에 들어가지 않는 것을 의미한다.
lockSupport의 대표적인 기능은
- park(): 스레드를 WAITING상태로 변경한다.
- parkNanos(nanos): 스레드를 나노초 동안만 TIME_WAITING상태로 변경한다. 나노초가 지나면 다시 RUNNABLE상태로 변경한다.
- unpark(thread): WAITING 상태의 대상 스레드를 RUNNABLE 상태로 변경한다.
위 기능들로 특정 시간 이후에는 RUNNABLE상태로 돌아와 무한 대기 상태 문제를 해결할 수 있다. 하지만 이걸 사용하기에는 실제로 얼마나 많은 스레드가 특정 임계 영역에 있어서 대기하는지 모르기에 이를 해결해야 한다.
ReentrantLock
가장 일반적인 lock으로 lock()을 호출하여 lock을 획득하고, unlock()을 호출하여 lock을 해제한다. 수동으로 lock, unlock을 하기에 finally를 통해서 unlock을 선언하는 것이 안전하다.
- void lock(): lock을 획득한다. 만약 다른 스레드가 이미 lock을 획득했다면, 스레드가 WAITING상태로 전환한다.
- void lockInterruptibly(): lock 획득을 시도한다. 다른 스레드가 인터럽트 할 수 있도록 한다. 즉 WAITING상태, 대기 중일 때 인터럽트가 발생하면 InterruptedException이 발생하여 lock 획득을 포기한다.
- boolean tryLock(): lock 획득을 시도하고 즉시 성공 여부를 반환한다. 이미 다른 스레드가 lock을 얻은 경우 false를 반환한다.
- boolean unlock(): lock을 해제한다. lock을 가지고 있는 스레드가 아닌 다른 스레드가 호출하면 IllegalMonitorStateException이 발생할 수 있다.
lock이 다른 스레드를 호출할 때 BLOCKED상태에 어떤 스레드가 호출될지 모른다.
이를 해결해기 위해서 ReentrantLock는 공정 모드(Fair mode)와 비공정 모드(Non-fair mode)로 설정이 가능하게 했다.
new ReentrantLock(true)위 코드처럼 하면 공정 모드(Fair mode)로 대기 큐에서 먼저 대기한 스레드가 먼저 lock을 획득한다. 이를 통해서 무한 대기 문제를 해결할 수 있게 되었다. 하지만 성능이 저하가 될 수 있다. 비공정 모드(Non-fair mode) 면 기존처럼 실행되는 lock이라고 생각하면 된다.
Object
멀티스레드를 고려해서 자바에서 만든 언어다.
- Object.wait(): 현재 스레드가 가진 락을 반납하고 WAITING 한다.
- Object.notify(): 대기 중인 스레드 중 하나를 깨운다.
- Object.notifyAll(): 대기 중인 모든 스레드를 깨운다.
Condition
ReentrantLock을 사용하는 스레드가 대기하는 공간이다.
Condition condition = lock.newCondition()위 코드처럼 lock.newCondition()을 통해서 스레드 공간을 만든다. lock(ReentrantLock)을 사용하는 경우 스레드 대기 공간을 직접 만들어 사용한다
- condition.await(): 지정한 condition에 현재 스레드를 WAITING상태로 보관한다.
- condition.signal(): 지정한 condition에서 대기 중인 스레드를 하나 깨운다. Object.notify()은 누구든 깨어날 수 있지만, Condition은 Queue 구조로, 일반적으로는 FIFO 순서로 깨운다.
BlockingQueue
스레드를 차단할 수 있는 큐이다. 큐의 기본 작업에 블로킹 연산을 추가하여 큐가 가득 찼을 때나 항목을 추가하려는 스레드, 큐가 비었을 때 항목을 제거하려는 스레드를 대기상태로 만든다.
BlockingQueue의 구현체는
- ArrayBlockingQueue: 배열 기반으로 구현, 버퍼의 크기가 고정되어 있다.
- LinkedBlockingQueue: 링크 기반으로 구현, 버퍼의 크기를 고정하거나 조절이 가능하다.
- PriorityBlockingQueue: 요소를 우선순위에 따라 저장한다.
블로킹 연산
특정 조건이 충족될 때까지 스레드를 일시중지 시키는 연산이다. 연산이 완료될 때까지 스레드를 대기 상태로 만든다.
출처
https://mangkyu.tistory.com/258
https://steady-coding.tistory.com/593
'Java' 카테고리의 다른 글
| [Java] I/O에 대한 공부 (1/2) (1) | 2024.12.31 |
|---|---|
| [Java] 제네릭에 대한 공부 (0) | 2024.10.31 |
| [Java] 예외처리에 대한 공부 (1) | 2024.09.29 |
| [Java] 다형성에 대한 공부 (1) | 2024.05.01 |
| [Java] 상속과 구현에 대한 공부 (0) | 2024.04.12 |


